在大数据时代,高效的数据处理和存储服务是支撑各类应用系统的基石。HBase作为一款分布式的、面向列的开源数据库,凭借其高可靠性、高性能和强大的可扩展性,成为了海量数据存储与实时查询的重要选择。本文将深入解析HBase的数据读写流程,揭示其作为数据处理和存储服务核心组件的工作原理。
一、HBase架构概览
在理解读写流程之前,需先了解HBase的基本架构。HBase构建在Hadoop HDFS之上,采用Master-Slave架构:
- HMaster:负责管理元数据(表结构、Region分配等)、负载均衡和故障恢复。
- RegionServer:实际存储和管理数据的节点,每个RegionServer管理多个Region(数据分片)。
- ZooKeeper:作为协调服务,负责维护集群状态、Master选举以及RegionServer的注册与发现。
- HDFS:提供底层持久化存储,保证数据的高可靠性和高可用性。
数据在逻辑上被组织成表(Table),表按行键(RowKey)范围横向切分为多个Region,每个Region又由多个列族(Column Family)组成,列族内的数据按列进行存储。
二、HBase数据写入流程
写入流程是HBase保证数据持久化和高性能的关键。一次完整的Put操作主要经历以下步骤:
- 客户端发起请求:客户端通过ZooKeeper获取
hbase:meta表(旧版本为.META.)的位置信息。hbase:meta表存储了所有用户表Region的元数据,包括RegionServer的分配情况。
- 定位目标Region:客户端缓存
hbase:meta信息,根据待写入数据的RowKey,查找其所属的Region及所在的RegionServer地址。
- 发送写请求:客户端将写请求(包含RowKey、列族、列限定符、时间戳、值等)直接发送给对应的RegionServer。
- RegionServer处理写入:
- WAL写入:RegionServer首先将数据变更以追加(Append)方式写入预写日志(Write-Ahead Log, WAL)。WAL是HBase实现数据持久化和故障恢复的关键机制,确保即使在内存数据丢失(如RegionServer崩溃)的情况下,也能通过重放WAL恢复数据。
- MemStore写入:数据被写入对应Region的MemStore中。MemStore是一个按列族组织的、有序的内存缓冲区。写入MemStore后,对客户端而言,写入操作即告完成,保证了低延迟。
- MemStore刷写(Flush):当MemStore的大小达到阈值(
hbase.hregion.memstore.flush.size)或整个RegionServer的MemStore总大小达到上限时,会触发刷写操作。RegionServer将MemStore中的数据排序后,以HFile格式批量写入HDFS。刷写完成后,会生成一个新的HFile,并清空旧的MemStore。此过程是异步的,不影响后续写入。
- 合并与压实(Compaction):随着刷写次数增多,HDFS上会积累大量小文件(HFile)。HBase会定期执行Compaction操作,将多个小HFile合并为更大的HFile,并清理已标记删除或过期的数据,以优化读取性能并回收存储空间。
三、HBase数据读取流程
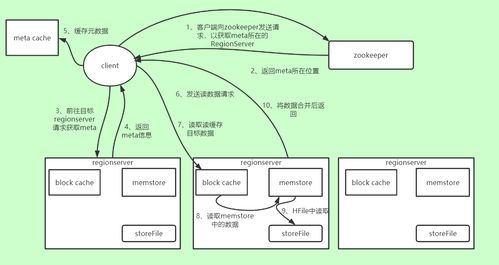
HBase的读取流程设计旨在通过多层缓存和高效的查找策略,实现快速的数据检索。一次Get或Scan操作的核心步骤如下:
- 客户端定位Region:与写入流程类似,客户端首先通过ZooKeeper和
hbase:meta表定位目标RowKey所在的RegionServer。
- 发送读请求:客户端将读请求发送至目标RegionServer。
- RegionServer多级查询:RegionServer接收到请求后,会并行地从多个可能包含目标数据的存储层次中查找,并按照时间戳等规则合并结果,返回最新版本的数据。查找顺序遵循“最近写入优先”原则,通常包括:
- BlockCache:这是读缓存,存储在JVM堆外内存(默认)。它缓存最近读取过的HFile数据块(Block),如果请求的数据块在BlockCache中命中,则直接返回,速度最快。
- MemStore:查询当前活跃的MemStore。因为MemStore中存储着尚未刷写到磁盘的最新数据。
- StoreFile (HFile):如果上述两级都没有找到全部所需数据,则需扫描磁盘上的HFile。HFile内部数据按RowKey有序存储,并建有索引(布隆过滤器、块索引等),RegionServer可以利用这些索引快速定位到可能包含目标RowKey的HFile数据块,然后将其加载到BlockCache并返回数据。
- 结果合并与返回:RegionServer将从MemStore和多个HFile中读取到的数据(可能包含同一单元格的多个版本)进行合并,根据时间戳过滤掉已删除或过期的数据,将最终结果返回给客户端。
四、作为数据处理和存储服务的优化与考量
理解HBase的读写流程,有助于在构建数据处理和存储服务时进行有效优化:
- RowKey设计:RowKey决定了数据在Region间的分布和存储顺序,是影响读写性能的最关键因素。良好的设计应保证负载均衡,并利用其有序性优化Scan查询。
- 列族与版本管理:合理设置列族数量、数据版本数和TTL(生存时间),可以控制存储结构和数据生命周期。
- 内存配置:调整MemStore大小、BlockCache大小及其比例(堆内/堆外),对读写性能有直接影响。
- 刷写与压实策略:调整刷写阈值、压实策略(Minor/Major)和触发条件,可以平衡写入性能、读取性能与存储效率。
- 一致性模型:HBase提供强一致性和时间线一致性(Timeline Consistency)等模型,根据应用场景选择合适的一致性级别。
###
HBase的数据读写流程,深度融合了内存计算、预写日志、多层缓存、LSM-Tree存储模型等经典设计思想,使其能够优雅地平衡高吞吐量写入与低延迟随机读取的需求。作为大数据生态中重要的在线数据处理和存储服务组件,深入掌握其内部机制,是进行系统性能调优、故障排查和架构设计的前提。在实际应用中,结合具体的业务场景和数据特征,对HBase进行恰当的配置与设计,才能充分发挥其作为海量数据实时存储与访问基石的核心价值。